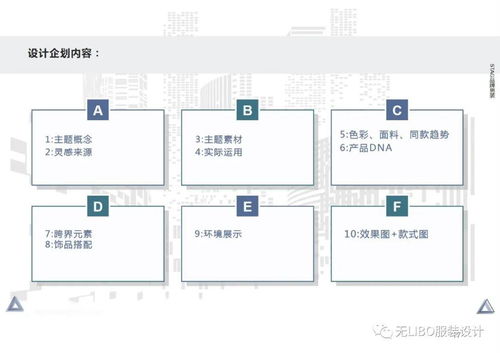
MapReduce分布式計算框架 分而治之思想與軟硬件技術支撐
《Hadoop/Spark大數(shù)據(jù)技術(微課版)》(曾國蓀、曹潔 編著)第三章深入剖析了MapReduce這一經(jīng)典的分布式計算框架。本章內容的核心在于理解其設計思想與實現(xiàn)機制,其中“分而治之”是靈魂,而計算機軟硬件技術則是其得以高效運行的堅實基石。
一、核心思想:分而治之
MapReduce框架的核心設計哲學正是古老的“分而治之”(Divide and Conquer)策略在現(xiàn)代大規(guī)模數(shù)據(jù)計算場景下的完美體現(xiàn)。這一思想貫穿于計算任務處理的始終:
- “分”(Map階段):
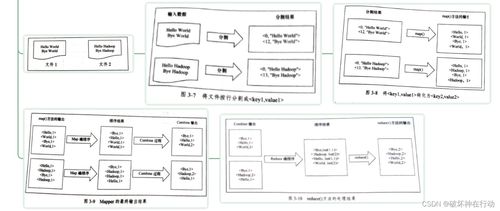
- 數(shù)據(jù)分片:框架首先將海量的輸入數(shù)據(jù)自動切割成多個獨立、大小適宜的數(shù)據(jù)塊(Split),這些數(shù)據(jù)塊被分布式地存儲在不同的計算節(jié)點上。
- 任務分發(fā):系統(tǒng)為每個數(shù)據(jù)分片創(chuàng)建一個Map任務,并將其調度到存儲有該數(shù)據(jù)分片副本的節(jié)點上執(zhí)行,實現(xiàn)了“計算向數(shù)據(jù)遷移”,極大減少了數(shù)據(jù)網(wǎng)絡傳輸開銷。
- 并行處理:每個Map任務獨立地處理一小部分數(shù)據(jù),讀取輸入分片,調用用戶定義的Map函數(shù),輸出一系列中間鍵值對。成千上萬個Map任務可以并行運行,這是處理速度得以飛躍的關鍵。
- “治”(Reduce階段):
- 洗牌與排序:框架會自動將Map階段輸出的所有中間鍵值對,按照鍵(Key)進行重新分發(fā)與排序,確保所有相同鍵的數(shù)據(jù)都被匯集到同一個Reduce任務進行處理。這個過程稱為“Shuffle”,是連接Map和Reduce的橋梁。
- 歸約匯總:每個Reduce任務接收針對某一組鍵的所有中間值,調用用戶定義的Reduce函數(shù),對這些值進行歸約、匯總、過濾或其他計算,最終生成最終的輸出結果。
通過“分而治之”,一個龐大的、看似無法單機處理的計算問題,被分解為大量可并行執(zhí)行的細小任務,再將其結果合并,從而高效地解決了大數(shù)據(jù)計算的難題。
二、計算機軟硬件技術的深度開發(fā)與支撐
MapReduce框架的落地與高效運行,離不開底層一系列計算機軟硬件技術的深度開發(fā)和協(xié)同工作。書中第三章也著重探討了這一層面的支撐:
- 硬件技術基礎:
- 廉價商用硬件集群:MapReduce設計之初就面向由普通PC服務器組成的集群,而非依賴昂貴的大型機或專用設備。這得益于現(xiàn)代多核CPU、大容量硬盤和高速網(wǎng)絡等硬件的普及與性能提升。
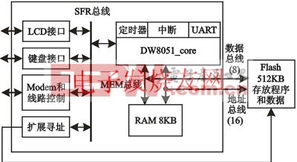
- 分布式存儲(HDFS):作為MapReduce的“孿生兄弟”,HDFS提供了高可靠、高吞吐量的數(shù)據(jù)存儲服務。它將大文件分塊存儲在多臺機器上,并通過多副本機制保證容錯,這直接為Map階段“計算向數(shù)據(jù)遷移”提供了可能。
- 軟件系統(tǒng)與核心開發(fā):
- 資源管理與調度(YARN):在Hadoop 2.0之后,YARN作為統(tǒng)一的資源管理平臺,負責整個集群的計算資源(CPU、內存)管理和任務調度。它將JobTracker的功能拆分為ResourceManager和ApplicationMaster,使得MapReduce作業(yè)的調度更加高效、靈活,并支持多種計算框架共存。
- 容錯機制:這是MapReduce框架軟件設計的精髓。通過任務級別的容錯(失敗的任務會被自動重新調度到其他節(jié)點執(zhí)行)、數(shù)據(jù)冗余存儲(HDFS多副本)以及推測執(zhí)行(對“慢任務”啟動備份任務)等機制,框架能夠在由成千上萬不穩(wěn)定節(jié)點組成的大規(guī)模集群中穩(wěn)定運行。
- 數(shù)據(jù)本地化優(yōu)化:調度器會優(yōu)先將Map任務分配給存儲有輸入數(shù)據(jù)塊的節(jié)點,這一軟件的優(yōu)化策略極大地減少了集群網(wǎng)絡帶寬的壓力,提升了整體性能。
- 序列化與RPC通信:框架內部定義了緊湊、高效的序列化機制(如Writable接口),用于節(jié)點間的數(shù)據(jù)傳輸;基于RPC的通信模型保障了各個組件間穩(wěn)定可靠的遠程調用。
###
第三章的思維導圖清晰地勾勒出MapReduce的雙重脈絡:在頂層,是清晰優(yōu)雅的“分而治之”計算模型,它簡化了分布式編程的復雜度;在底層,則是一整套針對大規(guī)模商用硬件集群深度開發(fā)的、復雜而精妙的軟件系統(tǒng)技術。正是這種“簡單接口”與“復雜實現(xiàn)”的結合,使得MapReduce成為大數(shù)據(jù)時代第一個得以廣泛應用和驗證的分布式計算范式,并為后續(xù)如Spark等更高效框架的出現(xiàn)奠定了堅實的思想和技術基礎。理解這一章,不僅在于掌握MapReduce的工作流程,更在于領悟如何利用軟硬件技術將一種強大的計算思想工程化、落地化。
如若轉載,請注明出處:http://m.jmlanyu.cn/product/57.html
更新時間:2026-04-08 00:28:28